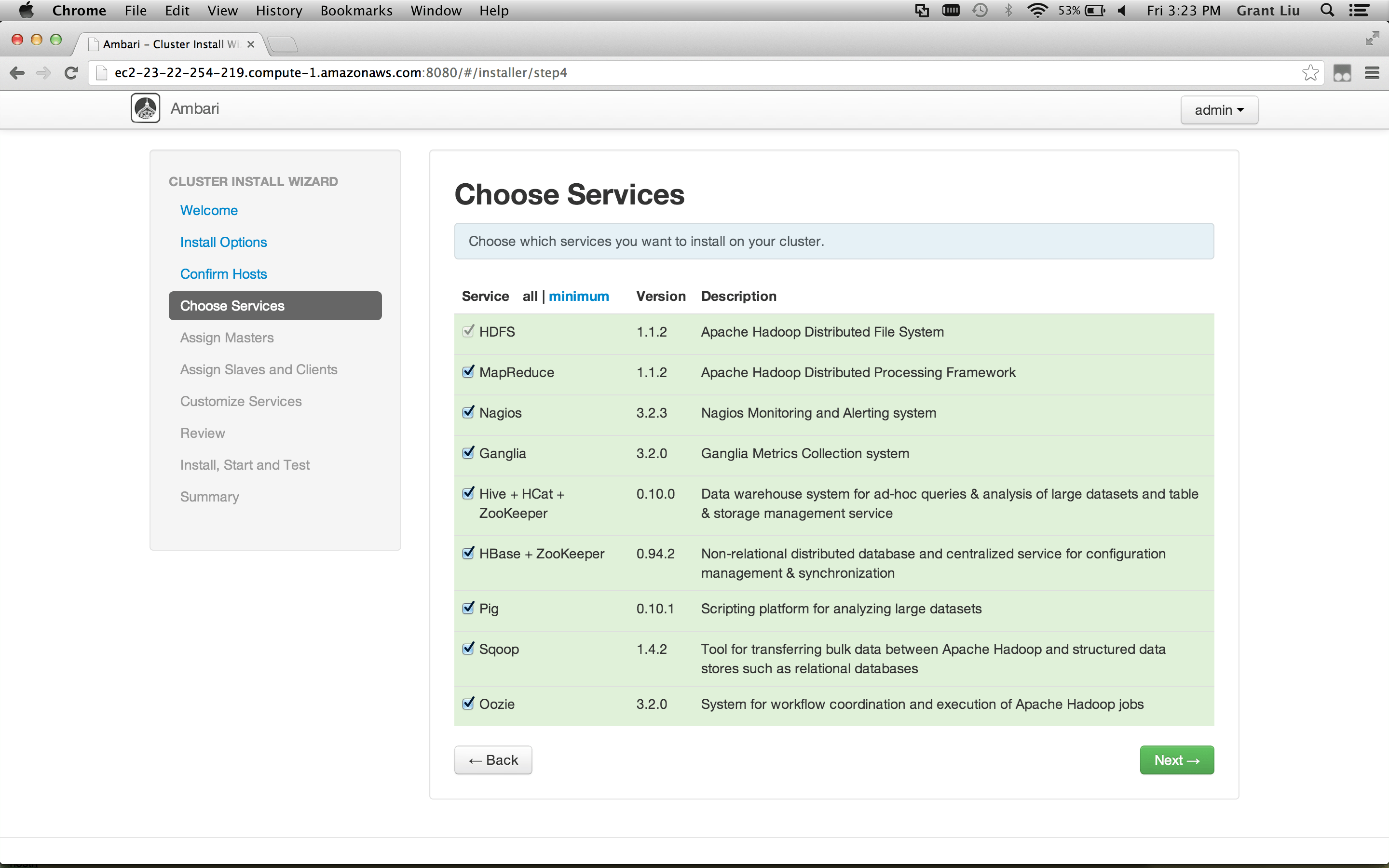
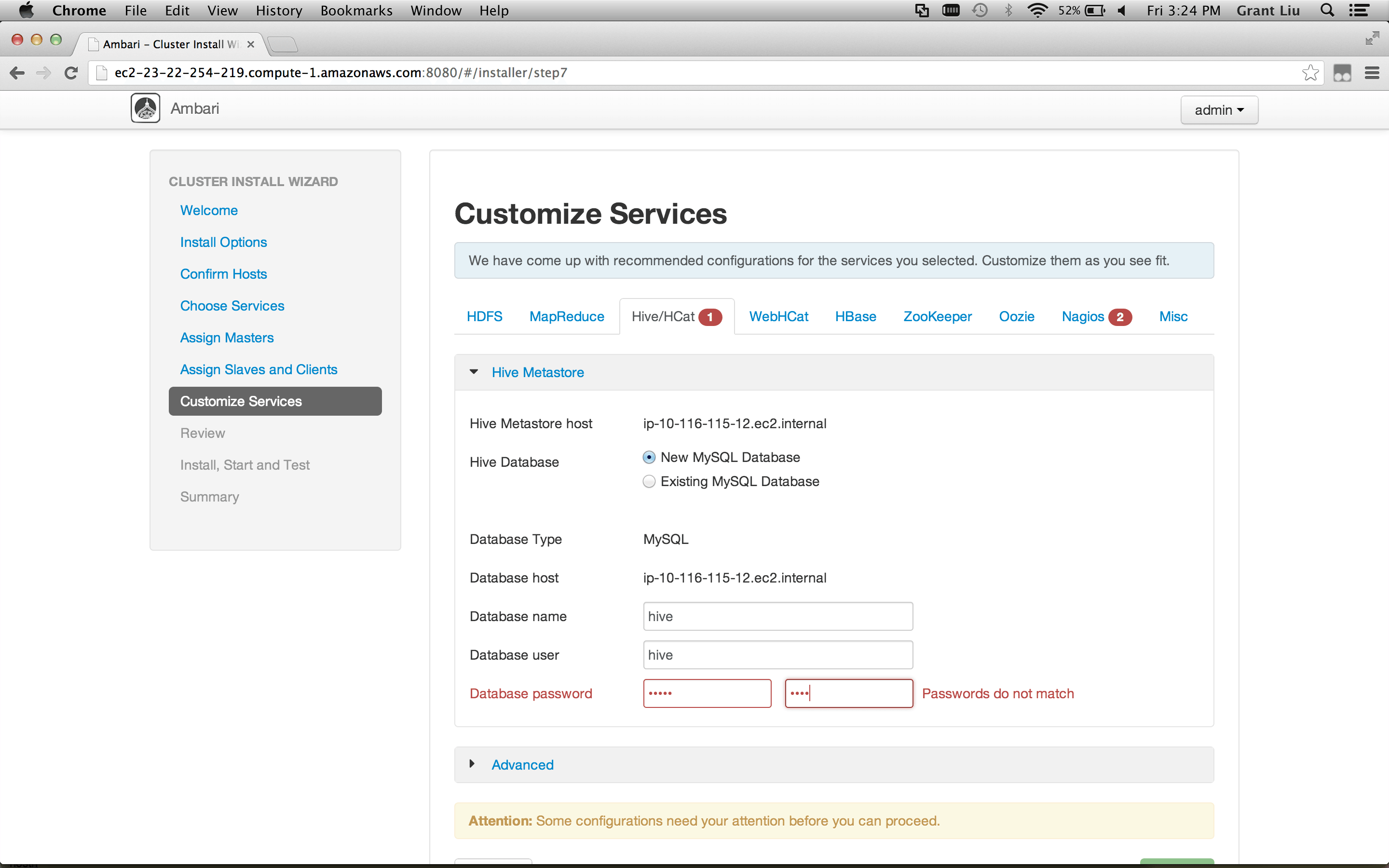
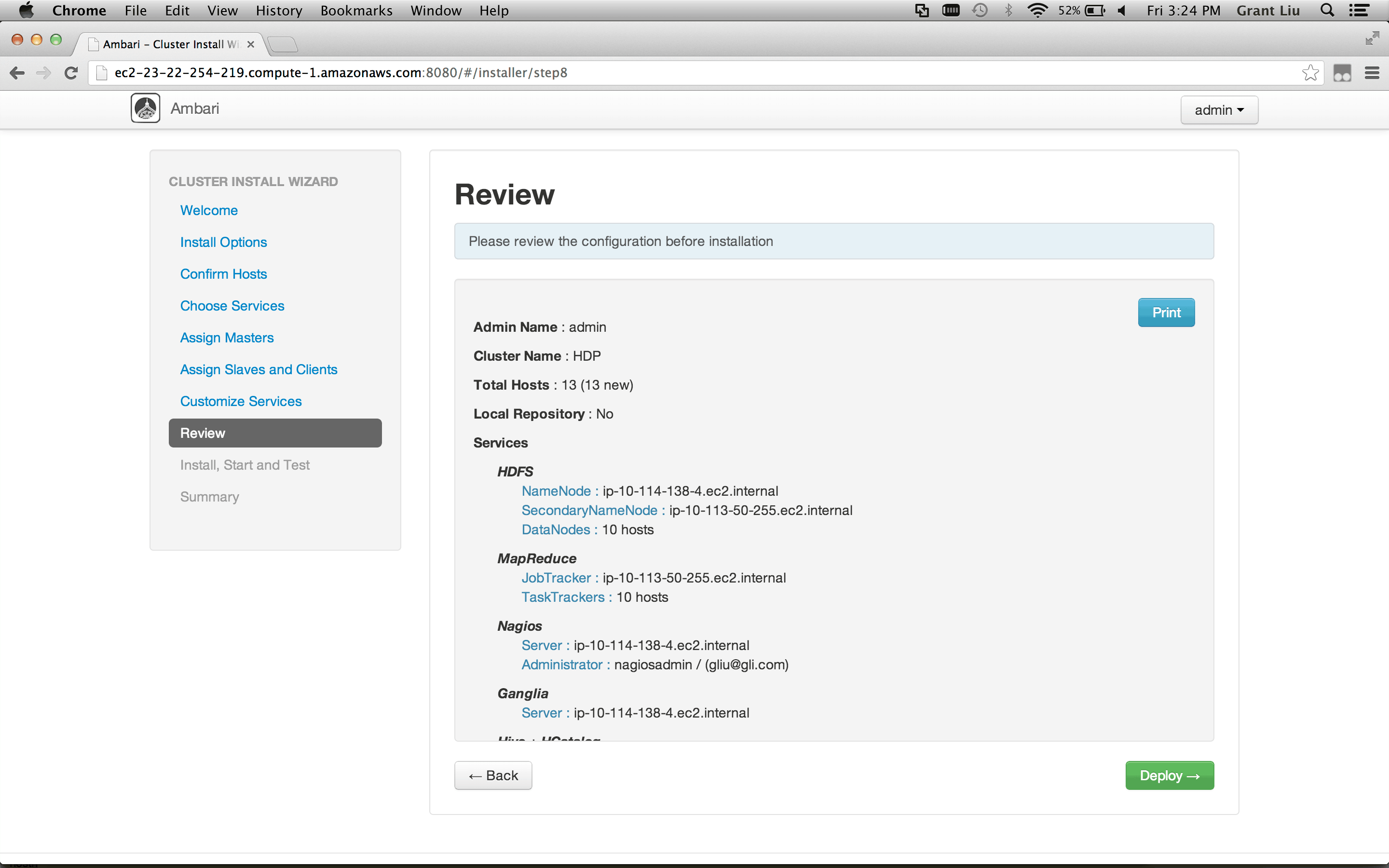
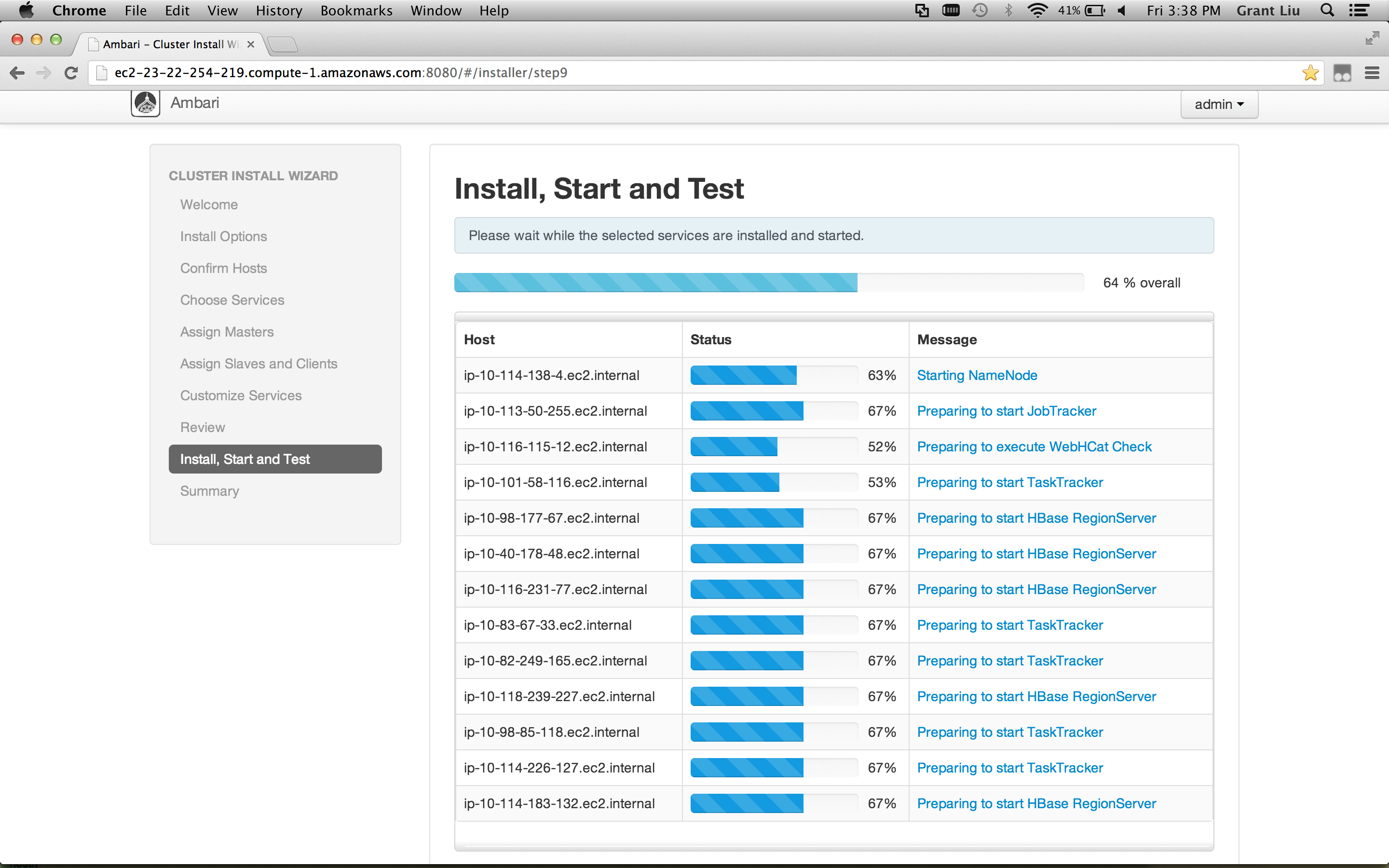
##### Authorization & Audit: allow users to specify access policies and enable audit around Hadoop from a central location via a UI, integrated with LDAP
- Goals:
- Install Apache Ranger on HDP 2.1
- Sync users between Apache Ranger and LDAP
- Configure HDFS & Hive to use Apache Ranger
- Define HDFS & Hive Access Policy For Users
- Log into Hue as the end user and note the authorization policies being enforced
- Pre-requisites:
- At this point you should have setup an LDAP VM and a kerborized HDP sandbox. We will take this as a starting point and setup Ranger
- Contents:
- [Install Ranger and its User/Group sync agent](https://github.com/abajwa-hw/security-workshops/blob/master/Setup-ranger-21.md#install-ranger-and-its-usergroup-sync-agent)
- [Setup HDFS repo in Ranger](https://github.com/abajwa-hw/security-workshops/blob/master/Setup-ranger-21.md#setup-hdfs-repo-in-ranger)
- [HDFS Audit Exercises in Ranger](https://github.com/abajwa-hw/security-workshops/blob/master/Setup-ranger-21.md#hdfs-audit-exercises-in-ranger)
- [Setup Hive repo in Ranger](https://github.com/abajwa-hw/security-workshops/blob/master/Setup-ranger-21.md#setup-hive-repo-in-ranger)
- [Hive Audit Exercises in Ranger](https://github.com/abajwa-hw/security-workshops/blob/master/Setup-ranger-21.md#hive-audit-exercises-in-ranger)
- [Setup HBase repo in Ranger](https://github.com/abajwa-hw/security-workshops/blob/master/Setup-ranger-21.md#setup-hbase-repo-in-ranger)
- [HBase audit exercises in Ranger](https://github.com/abajwa-hw/security-workshops/blob/master/Setup-ranger-21.md#hbase-audit-exercises-in-ranger)
- Video:
- <a href="http://www.youtube.com/watch?feature=player_embedded&v=Qi-fxJTNhtY" target="_blank"><img src="http://img.youtube.com/vi/Qi-fxJTNhtY/0.jpg" alt="Authorization and Audit" width="240" height="180" border="10" /></a>
---------------------------
##### Install Ranger and its User/Group sync agent
- Download Ranger policymgr (security webUI portal) and ugsync (User and Group Agent to sync users from LDAP to webUI)
```
mkdir /tmp/xasecure
cd /tmp/xasecure
wget http://public-repo-1.hortonworks.com/HDP-LABS/Projects/XA-Secure/3.5.001/xasecure-policymgr-3.5.001-release.tar
wget http://public-repo-1.hortonworks.com/HDP-LABS/Projects/XA-Secure/3.5.001/xasecure-uxugsync-3.5.001-release.tar
tar -xvf xasecure-uxugsync-3.5.001-release.tar
tar -xvf xasecure-policymgr-3.5.001-release.tar
```
- Configure/install policymgr
```
cd /tmp/xasecure/xasecure-policymgr-3.5.001-release
vi install.properties
```
- No changes needed: just confirm the below are set this way:
```
authentication_method=NONE
remoteLoginEnabled=true
authServiceHostName=localhost
authServicePort=5151
```
- Start Ranger Admin
```
./install.sh
#enter hortonworks for the passwords
#You should see "XAPolicyManager has started successfully"
```
- Install user/groups sync agent (ugsync)
```
yum install ranger-usersync
#to uninstall: yum remove ranger_2_2_0_0_2041-usersync ranger-usersync
```
- Configure ugsync to pull users from LDAP
```
cd /tmp/xasecure/xasecure-uxugsync-3.5.001-release
vi install.properties
POLICY_MGR_URL = http://sandbox.hortonworks.com:6080
SYNC_SOURCE = ldap
SYNC_LDAP_URL = ldap://ipa.hortonworks.com:389
SYNC_LDAP_BIND_DN = uid=admin,cn=users,cn=accounts,dc=hortonworks,dc=com
SYNC_LDAP_BIND_PASSWORD = hortonworks
SYNC_LDAP_USER_SEARCH_BASE = cn=users,cn=accounts,dc=hortonworks,dc=com
SYNC_LDAP_USER_NAME_ATTRIBUTE = uid
```
- Install the service
```
./install.sh
```
- Start the service
```
./start.sh
```
- confirm Agent/Ranger started
```
ps -ef | grep UnixAuthenticationService
ps -ef|grep proc_ranger
```
- Open log file to confirm agent was able to import users/groups from LDAP
```
tail -f /var/log/uxugsync/unix-auth-sync.log
```
- Open WebUI and login as admin/admin. Your LDAP users and groups should appear in the Ranger UI, under Users/Groups
http://sandbox.hortonworks.com:6080
---------------------
##### Setup HDFS repo in Ranger
- In the Ranger UI, under PolicyManager tab, click the + sign next to HDFS and enter below (most values come from HDFS configs in Ambari):
```
Repository name: hdfs_sandbox
Username: xapolicymgr
Password: hortonworks
fs.default.name: hdfs://sandbox.hortonworks.com:8020
hadoop.security.authorization: true
hadoop.security.authentication: kerberos
hadoop.security.auth_to_local: (copy from HDFS configs)
dfs.datanode.kerberos.principal: dn/_HOST@HORTONWORKS.COM
dfs.namenode.kerberos.principal: nn/_HOST@HORTONWORKS.COM
dfs.secondary.namenode.kerberos.principal: nn/_HOST@HORTONWORKS.COM
Common Name For Certificate: (leave this empty)
```
- Make sure mysql connection works before setting up HDFS plugin
```
mysql -u xalogger -phortonworks -h localhost xasecure
```
- Setup Ranger HDFS plugin
**Note: if this were a multi-node cluster, you would run these steps on the host running the NameNode**
```
cd /tmp/xasecure
wget http://public-repo-1.hortonworks.com/HDP-LABS/Projects/XA-Secure/3.5.001/xasecure-hadoop-3.5.001-release.tar
tar -xvf xasecure-hadoop-3.5.001-release.tar
cd xasecure-hadoop-3.5.001-release
vi install.properties
POLICY_MGR_URL=http://sandbox.hortonworks.com:6080
REPOSITORY_NAME=hdfs_sandbox
XAAUDIT.DB.HOSTNAME=localhost
XAAUDIT.DB.DATABASE_NAME=xasecure
XAAUDIT.DB.USER_NAME=xalogger
XAAUDIT.DB.PASSWORD=hortonworks
```
- Start agent
```
./install.sh
```
- Edit HDFS settings via Ambari, under HDFS > Configs :
```
dfs.permissions.enabled = true
```
- Before restarting HDFS add below snippet to bottom of the file to start the Hadoop Security Agent with the NameNode service::
```
vi /usr/lib/hadoop/libexec/hadoop-config.sh
if [ -f ${HADOOP_CONF_DIR}/xasecure-hadoop-env.sh ]
then
. ${HADOOP_CONF_DIR}/xasecure-hadoop-env.sh
fi
```
- Restart HDFS via Ambari
- Create an HDFS dir and attempt to access it before/after adding userlevel Ranger HDFS policy
```
#run as root
su hdfs -c "hdfs dfs -mkdir /rangerdemo"
su hdfs -c "hdfs dfs -chmod 700 /rangerdemo"
```
- Notice the HDFS agent should show up in Ranger UI under Audit > Agents. Also notice that under Audit > Big Data tab you can see audit trail of what user accessed HDFS at what time with what result
##### HDFS Audit Exercises in Ranger:
```
su ali
hdfs dfs -ls /rangerdemo
#should fail saying "Failed to find any Kerberos tgt"
klist
kinit
#enter hortonworks as password. You may need to enter this multiple times if it asks you to change it
hdfs dfs -ls /rangerdemo
#this should fail with "Permission denied"
```
- Notice the audit report and filter on "REPOSITORY TYPE"="HDFS" and "USER"="ali" to see the how denied request was logged
- Add policy in Ranger and PolicyManager > hdfs_sandbox > Add new policy:
```
Resource path: /rangerdemo
Recursive: True
User: ali and give read, write, execute
Save > OK and wait 30s
```
- now this should succeed
```
hdfs dfs -ls /rangerdemo
```
- Now look at the audit reports for the above and filter on "REPOSITORY TYPE"="HDFS" and "USER"="ali" to see the how allowed request was logged
- Attempt to access dir *before* adding group level Ranger HDFS policy
```
su hr1
hdfs dfs -ls /rangerdemo
#should fail saying "Failed to find any Kerberos tgt"
klist
kinit
#enter hortonworks as password. You may need to enter this multiple times if it asks you to change it
hdfs dfs -ls /rangerdemo
#this should fail with "Permission denied". View the audit page for the new activity
```
- Add hr group to existing policy in Ranger
Under Policy Manager tab, click "/rangerdemo" link
under group add "hr" and give read, write, execute
Save > OK and wait 30s. While you wait you can review the summary of policies under Analytics tab
- Attempt to access dir *after* adding group level Ranger HDFS policy and this should pass now. View the audit page for the new activity
```
hdfs dfs -ls /rangerdemo
```
- Even though we did not directly grant access to hr1 user, since it is part of hr group it inherited the access.
---------------------
##### Setup Hive repo in Ranger
- In Ambari, add admins group and restart HDFS
hadoop.proxyuser.hive.groups: users, hr, admins
- In the Ranger UI, under PolicyManager tab, click the + sign next to Hive and enter below to create a Hive repo:
```
Repository name= hive_sandbox
username= xapolicymgr
password= hortonworks
jdbc.driverClassName= org.apache.hive.jdbc.HiveDriver
jdbc.url= jdbc:hive2://sandbox:10000/
Click Add
```
- install Hive plugin
**Note: if this were a multi-node cluster, you would run these steps on the host running Hive**
```
cd /tmp/xasecure
wget http://public-repo-1.hortonworks.com/HDP-LABS/Projects/XA-Secure/3.5.001/xasecure-hive-3.5.001-release.tar
tar -xvf xasecure-hive-3.5.001-release.tar
cd xasecure-hive-3.5.001-release
vi install.properties
POLICY_MGR_URL=http://sandbox.hortonworks.com:6080
REPOSITORY_NAME=hive_sandbox
XAAUDIT.DB.HOSTNAME=localhost
XAAUDIT.DB.DATABASE_NAME=xasecure
XAAUDIT.DB.USER_NAME=xalogger
XAAUDIT.DB.PASSWORD=hortonworks
```
- Start Hive plugin
```
./install.sh
```
- Replace the contents of this file with the below
```
vi /var/lib/ambari-server/resources/stacks/HDP/2.0.6/services/HIVE/package/templates/startHiveserver2.sh.j2
HIVE_SERVER2_OPTS=" -hiveconf hive.log.file=hiveserver2.log -hiveconf hive.log.dir=$5 -hiveconf hive.security.authenticator.manager=org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator "
{% if hive_authorization_enabled == True and str(hdp_stack_version).startswith('2.1') %}
# HiveServer 2 -hiveconf options
#HIVE_SERVER2_OPTS="${HIVE_SERVER2_OPTS} -hiveconf hive.security.authenticator.manager=org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator -hiveconf hive.security.authorization.manager=org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactory "
{% endif %}
HIVE_CONF_DIR=$4 /usr/lib/hive/bin/hiveserver2 -hiveconf hive.metastore.uris=" " ${HIVE_SERVER2_OPTS} > $1 2> $2 &
echo $!|cat>$3
```
- Restart Ambari agents
```
/etc/init.d/ambari-server stop
/etc/init.d/ambari-server start
/etc/init.d/ambari-agent stop
/etc/init.d/ambari-agent start
```
- Copy Ranger files to /etc/hive/conf
```
cd /etc/hive/conf.server/
cp xasecure-* ../conf/
```
- Make hive config changes and restart ambari
```
hive.security.authorization.manager = com.xasecure.authorization.hive.authorizer.XaSecureAuthorizer
hive.security.authorization.enabled = true
hive.exec.pre.hooks = org.apache.hadoop.hive.ql.hooks.ATSHook,com.xasecure.authorization.hive.hooks.XaSecureHivePreExecuteRunHook
hive.exec.post.hooks = org.apache.hadoop.hive.ql.hooks.ATSHook,com.xasecure.authorization.hive.hooks.XaSecureHivePostExecuteRunHook
#add to Custom hive-site.xml
hive.semantic.analyzer.hook = com.xasecure.authorization.hive.hooks.XaSecureSemanticAnalyzerHook
hive.server2.custom.authentication.class = com.xasecure.authentication.hive.LoginNameAuthenticator
hive.conf.restricted.list = hive.exec.driver.run.hooks, hive.server2.authentication, hive.metastore.pre.event.listeners, hive.security.authorization.enabled,hive.security.authorization.manager, hive.semantic.analyzer.hook, hive.exec.post.hooks
```
- Now restart Hive from ambari. If Hive fails to start due to metastore not coming up click on Hive > Summary > MysqlServer > Start MySql server
- You may also need to start data node if it went down (Ambari > HDFS > Service Action > Restart Data Nodes)
- Restart Hive once again as it did not cleanly restart
- Restart hue to make it aware of Ranger changes
```
service hue restart
```
- As an LDAP user, perform some Hive activity
```
su ali
kinit
#kinit: Client not found in Kerberos database while getting initial credentials
kinit ali
#hortonworks
beeline
!connect jdbc:hive2://sandbox.hortonworks.com:10000/default;principal=hive/sandbox.hortonworks.com@HORTONWORKS.COM
#hit enter twice
use default;
```
- Check Audit > Agent in Ranger policy manager UI to ensure Hive agent shows up now
- Restart hue to make it aware of Ranger changes
```
service hue restart
```
##### Hive Audit Exercises in Ranger
- create user dir for your LDAP user e.g. ali
```
su hdfs -c "hdfs dfs -mkdir /user/ali"
su hdfs -c "hdfs dfs -chown ali /user/ali"
```
- Sign out of Hue and sign back in as ali/hortonworks
- Run the below queries using the Beeswax Hue interface or beeline
```
show tables;
use default;
```
- Check Audit > Agent in Ranger policy manager UI to ensure Hive agent shows up now
- Create hive policies in Ranger for user ali
```
db name: default
table: sample_07
col name: code description
user: ali and check "select"
Add
```
```
db name: default
table: sample_08
col name: *
user: ali and check "select"
Add
```
- Save and wait 30s. You can review the hive policies in Ranger UI under Analytics tabs
- these will not work as user does not have access to all columns of sample_07
```
desc sample_07;
select * from sample_07 limit 1;
```
- these should work
```
select code,description from sample_07 limit 1;
desc sample_08;
select * from sample_08 limit 1;
```
- Now look at the audit reports for the above and notice that audit reports for Beeswax queries show up in Ranger
- Create hive policies in Ranger for group legal
```
db name: default
table: sample_08
col name: code description
group: legal and check “select”
Add
```
- Save and wait 30s
- create user dir for legal1
```
su hdfs -c "hdfs dfs -mkdir /user/legal1"
su hdfs -c "hdfs dfs -chown legal1 /user/legal1"
```
- This time lets try running the queries via Beeline interface
```
su legal1
klist
kinit
beeline
!connect jdbc:hive2://sandbox.hortonworks.com:10000/default;principal=hive/sandbox.hortonworks.com@HORTONWORKS.COM
#Hit enter twice when it prompts for password
```
- these should not work: "user does not have select priviledge"
```
desc sample_08;
select * from sample_08;
```
- these should work
```
select code,description from sample_08 limit 5;
```
- Now look at the audit reports for the above and notice that audit reports for beeline queries show up in Ranger
---------------------
##### Setup HBase repo in Ranger
- Start HBase using Ambari
**Note: if this were a multi-node cluster, you would run these steps on the host running HBase**
- **TODO: add HBase plugin config steps**
##### HBase audit exercises in Ranger
```
su ali
klist
hbase shell
list 'default'
create 't1', 'f1'
#ERROR: org.apache.hadoop.hbase.security.AccessDeniedException: Insufficient permissions for user 'ali/sandbox.hortonworks.com@HORTONWORKS.COM (auth:KERBEROS)' (global, action=CREATE)
```
---------------------
- Using Ranger, we have successfully added authorization policies and audit reports to our secure cluster from a central location |